Choice of Activation and Loss Functions
The choice of activation function is a critical part of neural network design. In the case of theperceptron, the choice of the sign activation function is motivated by the fact that a binary class label needs to be predicted. However, it is possible to have other types of situations where different target variables may be predicted. For example, if the target variable to bepredicted is real, then it makes sense to use the identity activation function, and the resulting algorithm is the same as least squares regression. If it is desirable to predict a probability of a binary class, it makes sense to use a sigmoid function for activating the output node, sothat the prediction
ŷ indicates the probability that the observed value,y, of the dependent variable is 1.
The negative logarithm of |y/2-0.5+ŷ|is used as the loss, assuming that y is coded from {-1,1}.
If
ŷ is the probability that y is 1, then |y/2-0.5+ŷ| is the probability that the correct value is predicted. This assertion is easy to verify by examining the two cases where y is 0 or 1. This loss function can be shown to be representative of the negative log likelihood of the training data .
The importance of nonlinear activation functions becomes significant when one moves from the single-layered perceptron to the multi-layered architectures discussed later in this chapter. Different types of nonlinear functions such as thesign,sigmoid,or hyperbolic tangents may be used in various layers.
We use the notation Φ to denote the activation function:

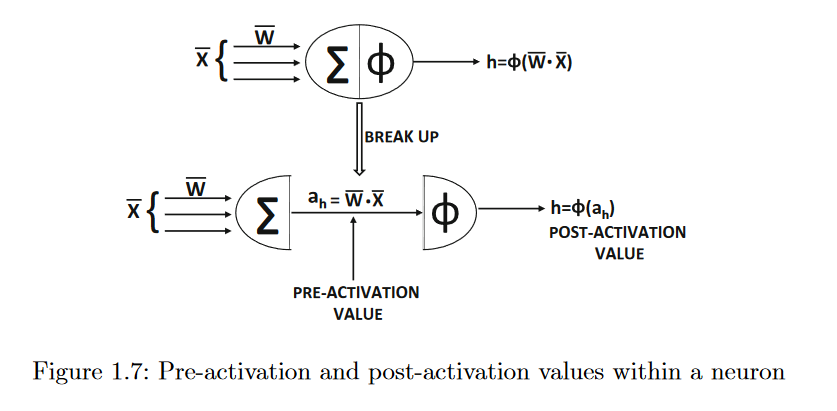
Therefore, a neuron really computes two functions within the node, which is why we have incorporated the summation symbol Σ as well as the activation symbol Φ within a neuron.The break-up of the neuron computations into two separate values is shown in the below image.
The value computed before applying the activation function Φ(.) will be referred to as the pre-activation value, whereas the value computed after applying the activation function isreferred to as the post-activation value. The output of a neuron is always the post-activation value, although the pre-activation variables are often used in different types of analyses, such as the computations of the back propagation algorithm discussed later in this post. The pre-activation and post-activation values of a neuron are shown in Figure
The most basic activation function Φ(.) is the identity or linear activation, which provides no nonlinearity:
Φ(ν)=ν
The linear activation function is often used in the output node, when the target is a realvalue. It is even used for discrete outputs when a smoothed surrogate loss function needs to be set up.
The classical activation functions that were used early in the development of neural networks were the sign, sigmoid, and the hyperbolic tangent functions:

While the sign activation can be used to map to binary outputs at prediction time, itsnon-differentiability prevents its use for creating the loss function at training time. Forexample, while the perceptron uses the sign function for prediction, the perceptron crite-rion in training only requires linear activation. The sigmoid activation outputs a value in(0,1), which is helpful in performing computations that should be interpreted as probabil-ities. Furthermore, it is also helpful in creating probabilistic outputs and constructing lossfunctions derived from maximum-likelihood models. The tanh function has a shape similar to that of the sigmoid function, except that it is horizontally re-scaled and verticallytranslated/re-scaled to [-1,1]. The tanh and sigmoid functions are related as follows
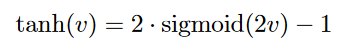
The tanh function is preferable to the sigmoid when the outputs of the computations are desired to be both positive and negative. Furthermore, its mean-centering and larger gradient
(because of stretching) with respect to sigmoid makes it easier to train. The sigmoid and the tanh functions have been the historical tools of choice for incorporating nonlinearity in theneural network. In recent years, however, a number of piecewise linear activation functions have become more popular:
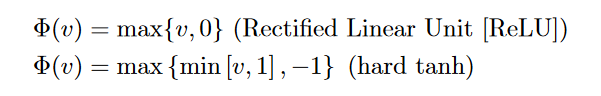
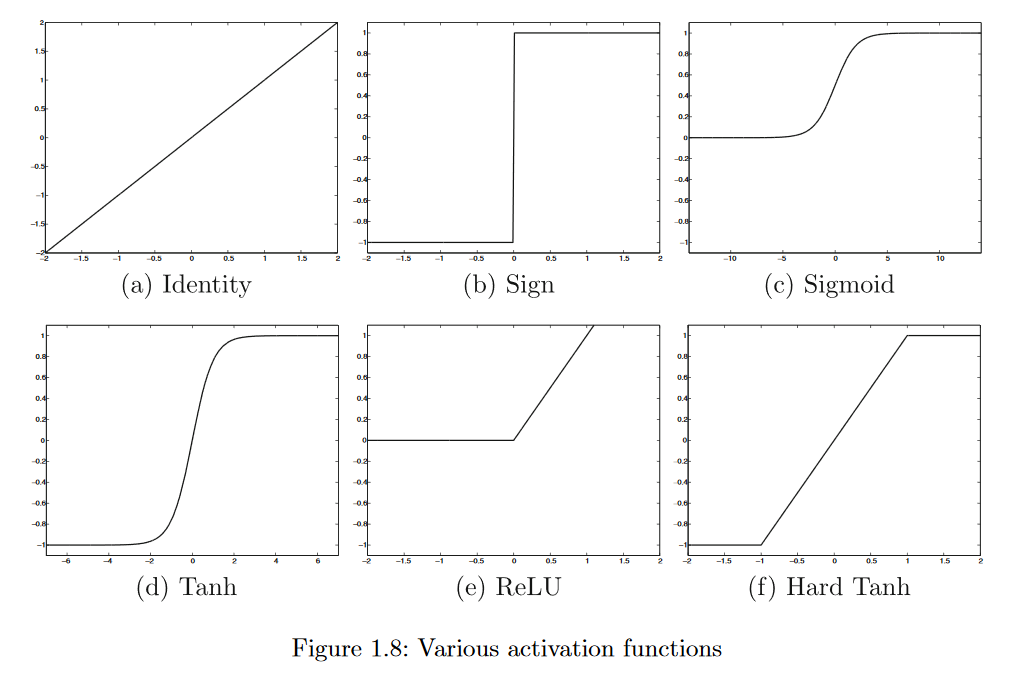
The ReLU and hard tanh activation functions have largely replaced the sigmoid and soft tanh activation functions in modern neural networks because of the ease in training multi-layered neural networks with these activation functions.Pictorial representations of all the aforementioned activation functions are illustrated in Figure1.8. It is noteworthy that all activation functions shown here are monotonic.Furthermore, other than the identity activation function, most 1 of the other activation functions saturate at large absolute values of the argument at which increasing further doesnot change the activation much.
As we will see later, such nonlinear activation functions are also very useful in multilayernetworks, because they help in creating more powerful compositions of different types of functions. Many of these functions are referred to as squashing functions, as they map theoutputs from an arbitrary range to bounded outputs. The use of a nonlinear activation plays a fundamental role in increasing the modeling power of a network. If a network used onlylinear activations, it would not provide better modeling power than a single-layer linearnetwork